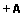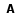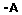Resumo: Os planos de saúde, tanto públicos quanto privados, vem acumulando grande quantidade de dados contendo informações ocultas que poderiam ajudar seus gestores na redução de custos das operadoras de planos de saúde e auxiliar no planejamento de programas de prevenção de doenças. Esses conhecimentos podem ser descobertos utilizando técnicas de Mineração de Dados (MD) para extração de informações relevantes e úteis. Nesse contexto pretende-se resolver a tarefa de classificação, que permite a descoberta de regras de previsão. Nesta dissertação apresenta-se uma abordagem para resolver a tarefa de classificação em MD na qual se propõe um algoritmo híbrido que utiliza Programação Genética (PG) juntamente com Algoritmo Cultural (AC), que é um algoritmo evolucionário baseado no processo de evolução cultural da humanidade. A abordagem implementada teve como estudo de caso os dados de uma operadora de planos de saúde suplementar, contendo informações administrativas e de procedimentos em hospitais, laboratórios e consultórios, relativos a beneficiários do estado de Santa Catarina. Esses dados foram pré-processados e preparados para serem utilizados pelo algoritmo proposto. Para avaliar a abordagem apresentada foram realizados experimentos com PG e com AC, onde o AC armazena conhecimentos e ajuda a guiar o processo evolutivo. Um desses conhecimentos armazena as impressões gerais, que são as crenças do usuário, permitindo medir o interesse nas regras encontradas. Com base nestes experimentos foi avaliada a capacidade do algoritmo proposto em encontrar regras em duas situações: considerando as impressões gerais do usuário e sem considerar as impressões gerais (crenças do usuário) e obtiveram-se bons resultados pelas duas abordagens. Avaliou-se também a capacidade do algoritmo em encontrar regras a partir de um conjunto de dados contendo pequenos disjuntos no qual conseguiu-se encontrar regras tanto dos grandes disjuntos como dos pequenos disjuntos, além de avaliar a maneira como as impressões gerais do usuário podem ser utilizadas pelo AC.
Abstract: Health plans, both public and private, have been accumulating large amounts of data containing hidden information that could help their managers to reduce costs of health insurance carriers and assist in planning programs for disease prevention. This knowledge can be discovered using Data Mining (DM) techniques for extracting information relevant and useful. In this context we intend to solve the task of classification that allows the discovery of prediction rules. This dissertation presents an approach to solving the classification task in MD which proposes a hybrid algorithm that uses Genetic Programming (GP) with Cultural Algorithm (CA), which is an evolutionary algorithm based on the process of cultural evolution of humanity. The approach was implemented as a case study data from an operator of health insurance supplement, containing administrative information and procedures in hospitals, laboratories and offices, for the beneficiaries of the state of Santa Catarina. These data were preprocessed and prepared for use by the algorithm. Experiments were performed to evaluate the approach with GP and CA, where CA stores knowledge and helps guide the evolutionary process. A knowledge of these stores general impressions, which are the beliefs of the user, allowing to measure the interest in the rules found. Based on these experiments we evaluated the ability of the algorithm to find rules in two situations: considering the general impressions of the user and without considering the general impression (the user's beliefs) and obtained good results by the two approaches. We also evaluated the ability of the algorithm to find rules from a data set containing small disjoint in which it was possible to find rules which belong to small disjoint and big disjoint, and assess how the general impression of the user can be used for CA. |